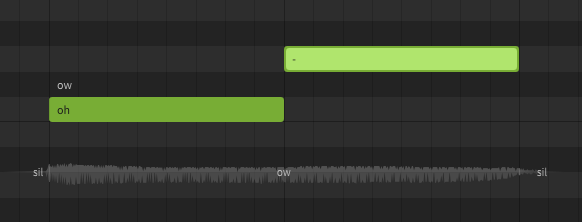
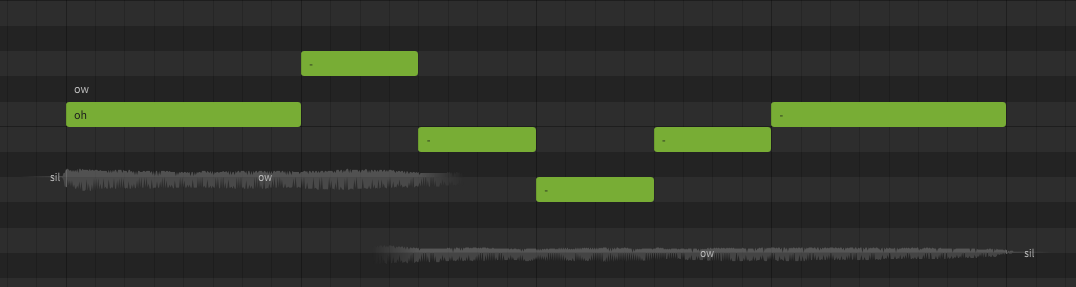
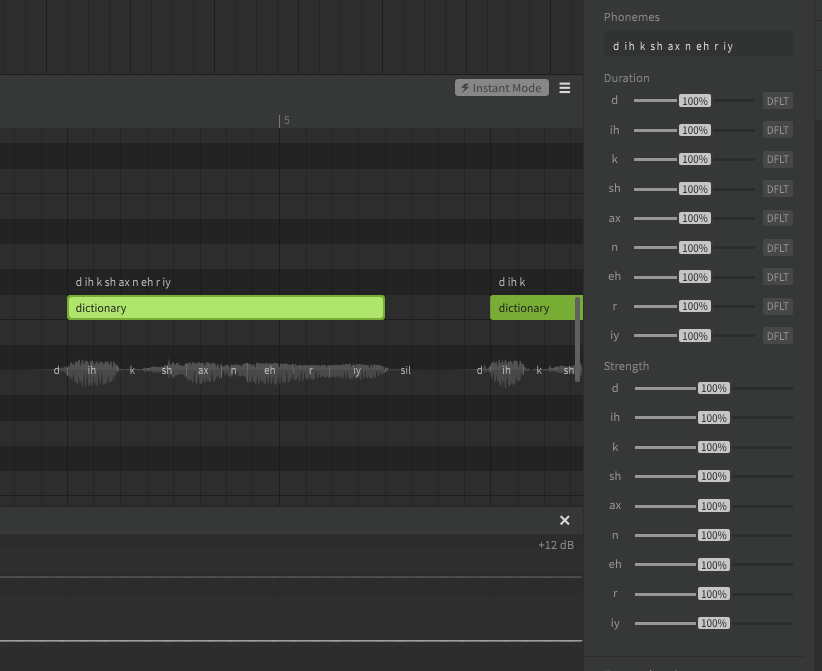
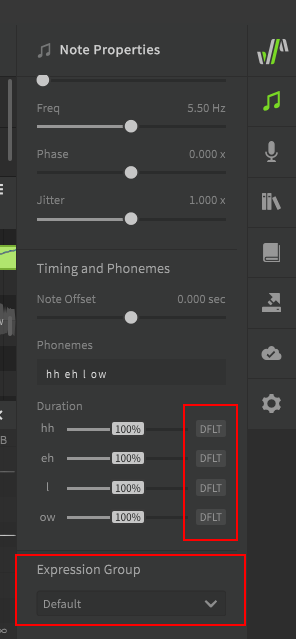
A phoneme is an individual sound that Synthesizer V Studio is capable of producing. The available list of phonemes is based on the language being used, and represents a list of all sounds a voice database is capable of producing (including transition sounds between each phoneme).
Cross-lingual synthesis is a feature available to AI voices that allows them access to the phoneme lists for English, Japanese, and Mandarin Chinese, regardless of what their default language is. It is important to keep in mind that AI voices still have a "native" language, and it is normal for them to have an accent when using cross-lingual synthesis.
Standard voices cannot use cross-lingual synthesis and are limited to the phoneme list for their native language.
Regarding Unsupported Languages
Each voice database product has a native language (English, Japanese, or Mandarin Chinese). AI voices using cross-lingual synthesis are able to access any of these supported languages.
Some users may use a large number of manual phoneme changes to make a voice database sing in a language it normally cannot sing in, however this is done by using the existing phoneme list to create a rough approximation of a different language, and certain pronunciations will be impossible when doing this simply because the voice database often cannot produce the necessary sounds for a language it does not support.
Put simply, the sounds a voice database can produce are limited by the phoneme lists it has access to.
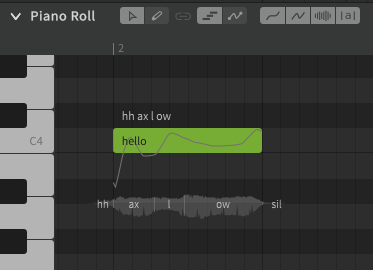
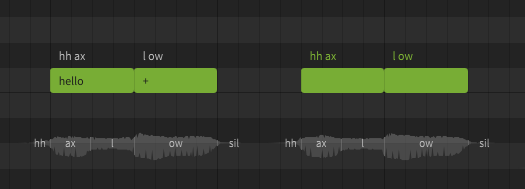
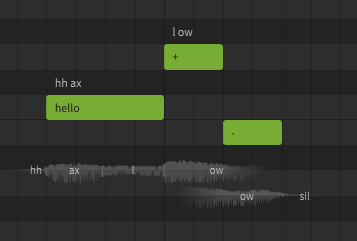
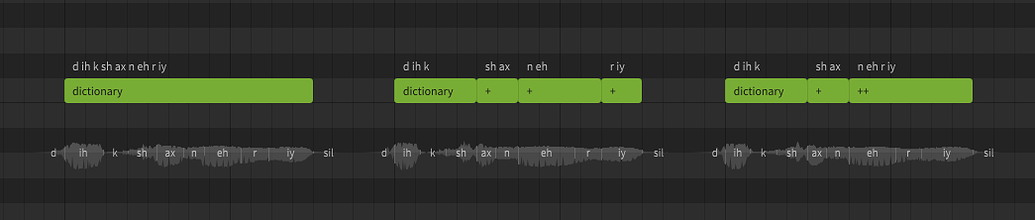
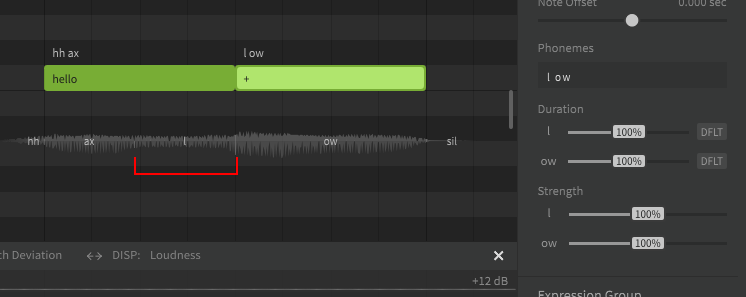
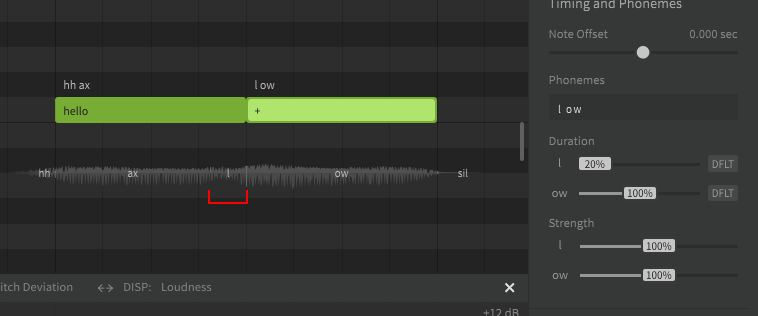
A lyric or word is the actual term represented by a sequence of phonemes. In Synthesizer V Studio, words do not directly affect the synthesized output. You could technically never enter the original lyrics or words and only ever enter the exact phonemes manually, and the resulting sound would not be any different. Realistically most users don't actually do that, because words are much easier to work with and taking advantage of the word-to-phoneme mapping allows for better workflow.
To be clear, words are a useful workflow tool, but phonemes are what actually influences the rendered output.
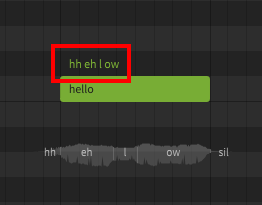
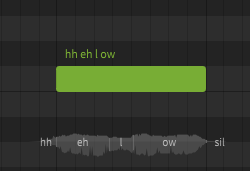
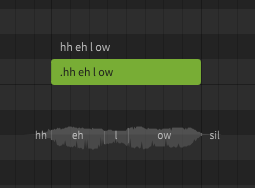
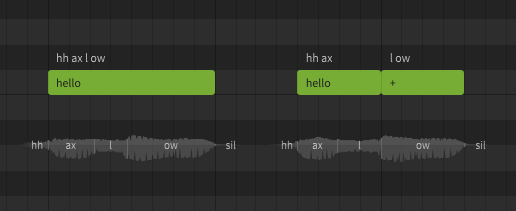
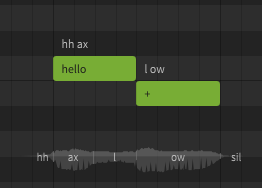
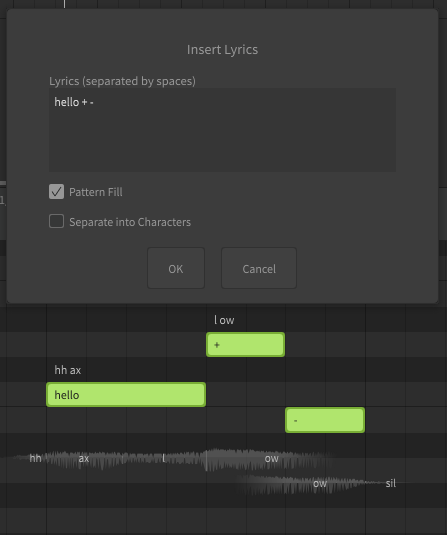
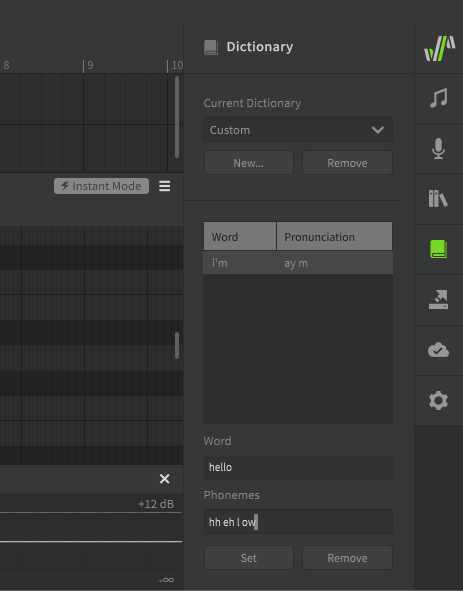
A dictionary is used to customize the mapping between words and phonemes. For example, by default "hello" is represented as hh ax l ow, but you may prefer it to be pronounced as hh eh l ow. Dictionaries are another workflow tool, and can save a lot of time if used effectively. Similar to words, there is nothing dictionaries can do that cannot also be accomplished by manually entering the phonemes for every note, it's just a tool we have at our disposal to make that process significantly faster and easier.